Maestro
综合介绍
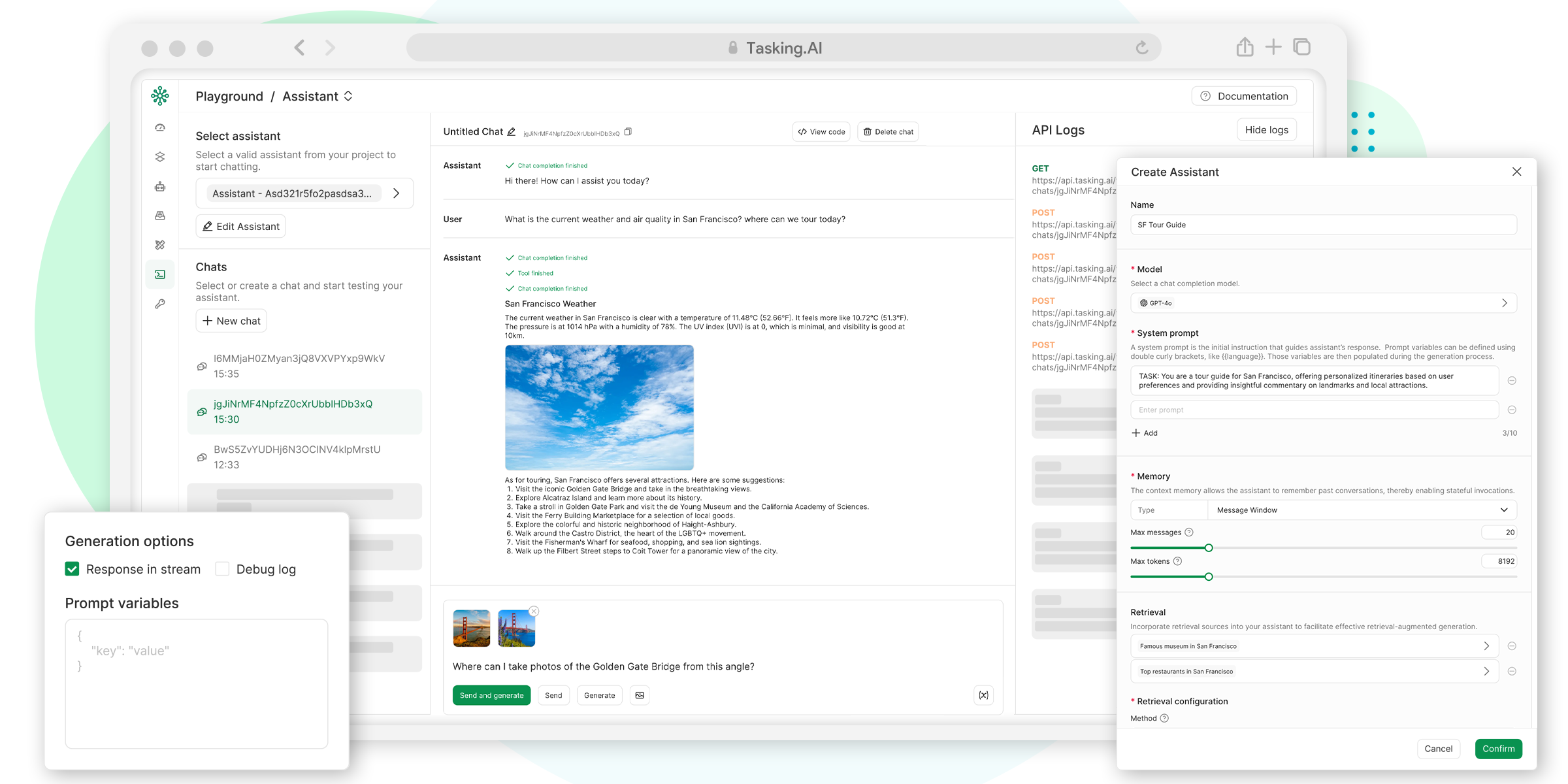
Maestro是一个可以部署在个人硬件上运行的AI研究平台。它被设计为一个协作式的、支持多用户使用的应用程序,旨在简化从开始到结束的复杂研究任务。用户可以先设定研究目标,然后上传相关的PDF文档做为知识库,之后AI智能体团队将接管后续的繁重工作。这些AI智能体不仅能从用户提供的文档中检索信息,还能从互联网上搜索资料,最终根据研究计划自动生成包含参考文献的详细报告。整个研究过程是透明的,用户可以随时查看AI的思考过程和研究路径。Maestro通过其独特的“WRITER”智能体框架,将规划、研究、反思和写作等多个环节分配给不同的专业AI智能体协同完成,从而实现高质量、结构化的研究成果输出。
功能列表
- 文档库管理:集中上传和管理PDF文档,支持为特定项目创建专门的文档组,以便AI能从精确的来源中提取信息。
- 自定义研究任务:用户可以设定研究任务的具体参数,包括范围、深度和重点,从而精确控制AI的调查方向。
- 与文档和网络聊天:通过聊天界面直接向文档或互联网提问,快速获取信息和灵感。
- 写作助手:辅助用户起草笔记、总结发现,或在遇到写作瓶颈时提供帮助。
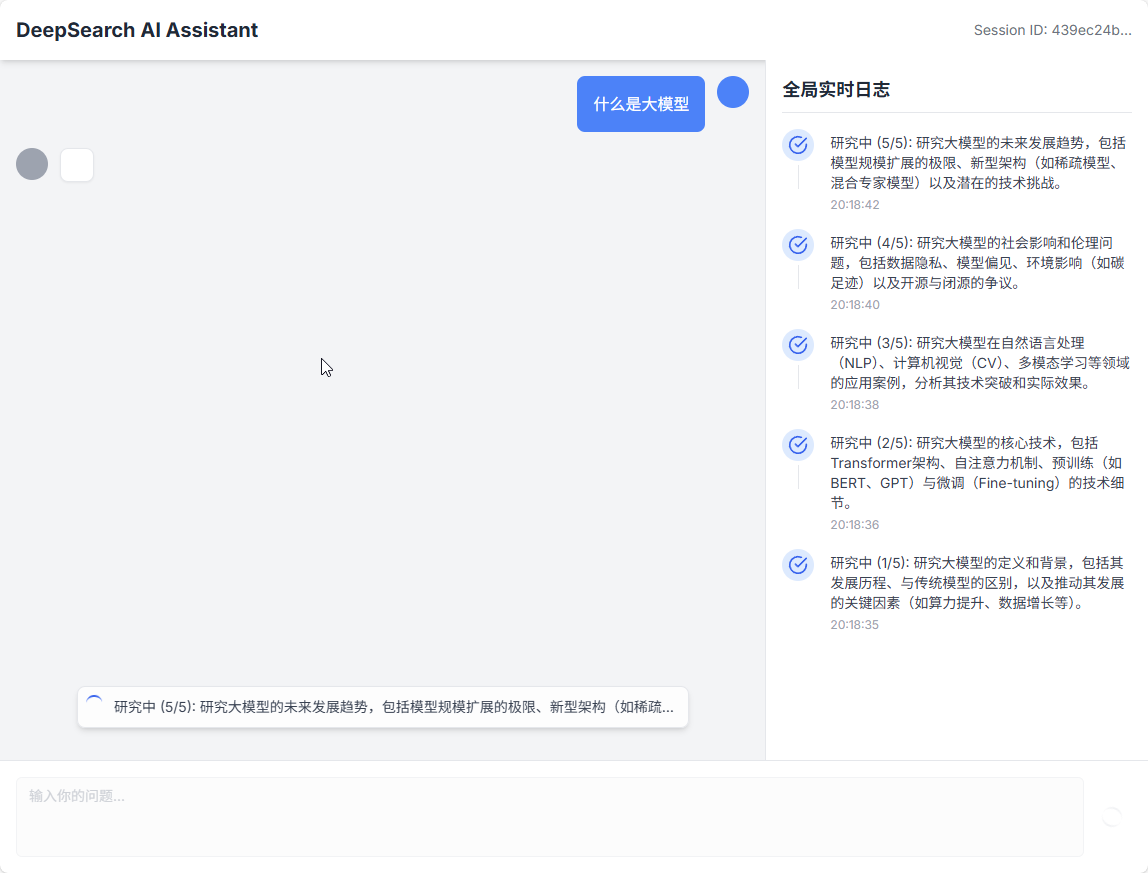
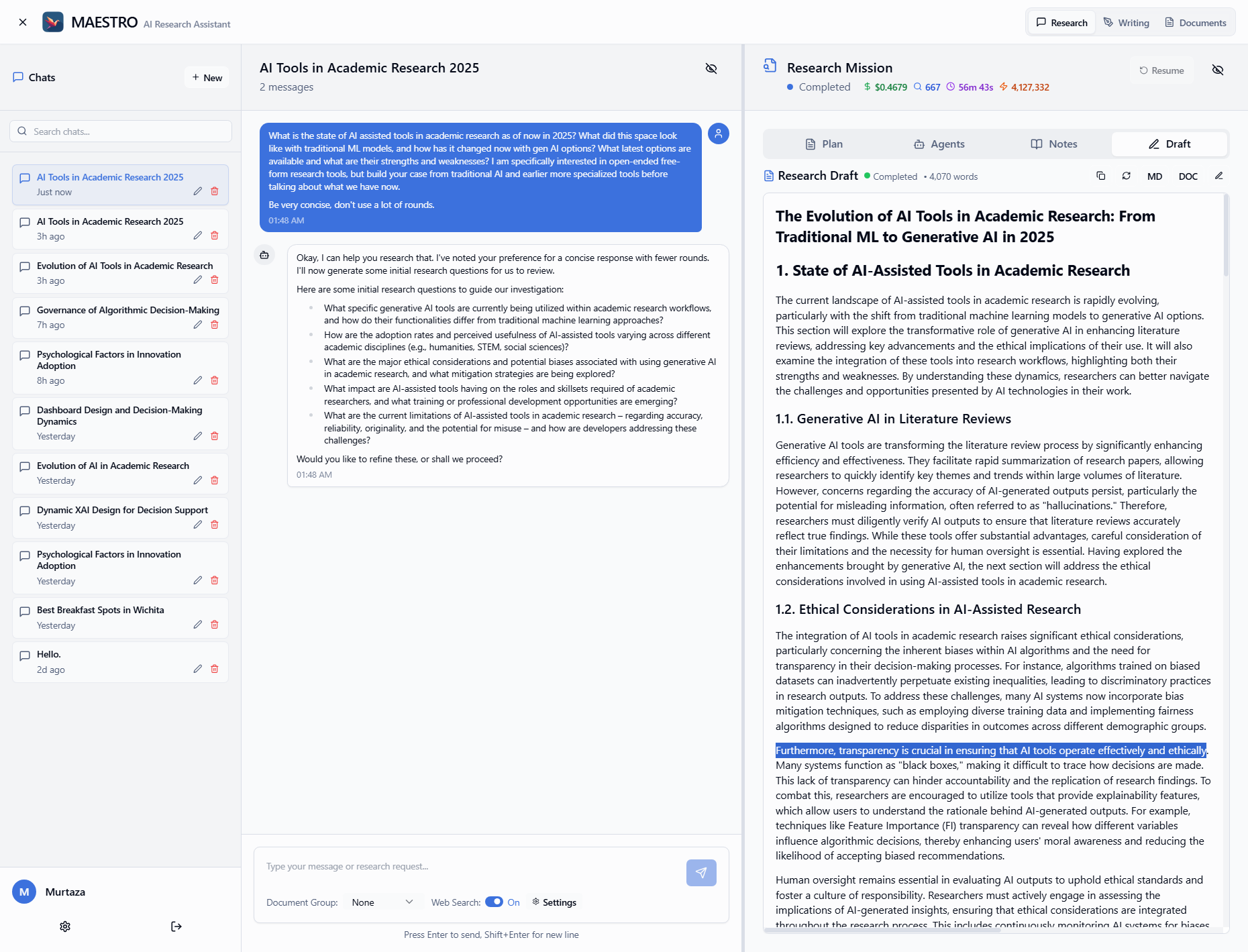
- 透明的研究过程:系统会展示AI生成的研究大纲和完整的调查路径,让用户清楚了解AI的每一步操作。
- 自动化笔记生成:研究智能体可以深入分析PDF文档或在线资源,并根据研究问题生成结构化的笔记。
- 详细的进度跟踪:实时跟踪研究任务的每一步,提供智能体活动和状态的详细更新。
- 洞察智能体推理过程:AI智能体会提供详细的反思笔记,解释其思考过程、决策和结论。
- 生成完整报告:根据研究计划和生成的笔记,系统最终会撰写一份包含参考文献的完整报告草稿。
- 完全自托管:支持连接本地的大语言模型(LLM)和私有元搜索引擎(SearXNG),确保整个研究流程的数据安全和私密性。
使用帮助
Maestro 作为一个复杂的AI研究系统,其核心优势在于它的多智能体协作框架和高度可定制化的自托管部署能力。以下是详细的使用帮助,旨在让用户能够顺利上手并充分利用其功能。
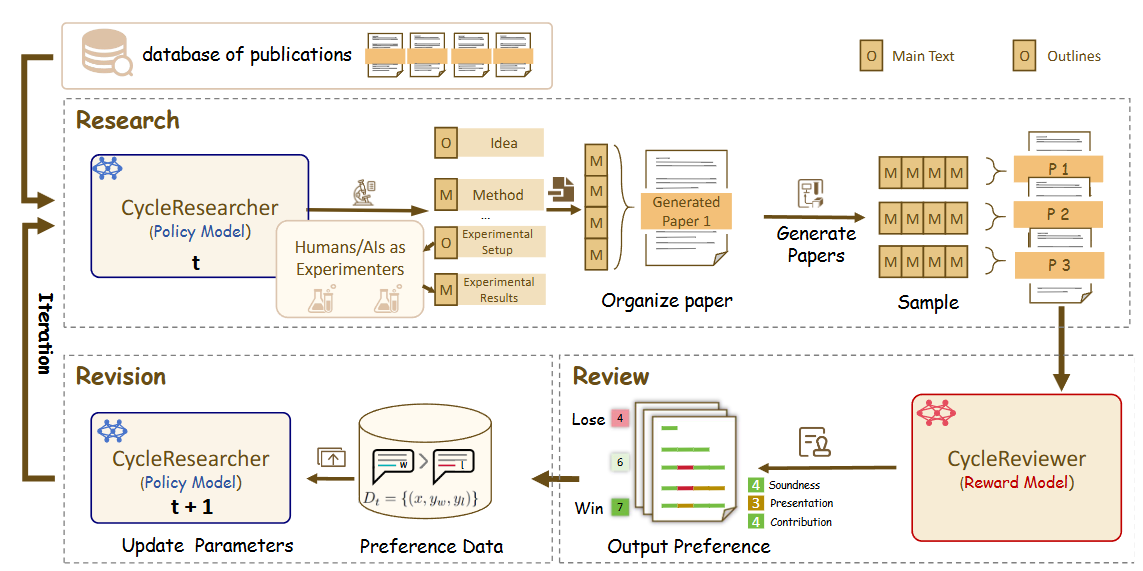
工作原理:WRITER智能体框架
Maestro并非使用单一的大模型,而是通过一个名为“WRITER”的代理框架,让一个由多个专业AI智能体组成的团队协同工作。这个框架保证了研究过程的结构化、透明化和严谨性。
核心智能体团队:
- 智能体控制器 (Orchestrator):作为总指挥,负责管理整个研究任务,将不同的任务分配给最合适的智能体,并确保工作流程顺利从一个阶段推进到下一个阶段。
- 规划智能体 (Strategist):接收用户的初始研究请求,并将其转化为一个结构化的、层次分明的研究计划和报告大纲。这份计划为后续所有工作提供了清晰的路线图。
- 研究智能体 (Investigator):执行研究计划,利用其工具(本地文档的RAG检索管道和网络搜索)来搜集相关信息和证据,并将结果整理成结构化的
ResearchNote对象。 - 反思智能体 (Critical Reviewer):这是Maestro分析深度的关键。该智能体持续审查其他智能体的工作,识别知识空白、信息矛盾或与计划的偏差。它的反馈会驱动系统进行迭代,从而提升研究质量。
- 写作智能体 (Synthesizer):将研究智能体整理好的研究笔记(
ResearchNote)串联起来,按照规划智能体设定的报告大纲,撰写出连贯、结构良好的报告内容。
研究过程的迭代与优化:
Maestro的研究过程不是线性的,而是通过两个关键的循环来模拟批判性思维,以确保最终成果的高质量。
- 研究-反思循环:研究智能体完成一轮信息收集后,反思智能体会介入并进行评判。它会提出诸如“证据是否存在空白?”或“不同来源的信息是否矛盾?”等问题。根据评判结果,反思智能体可以要求进行新一轮的研究,甚至要求规划智能体修改整个计划。这个循环会一直持续,直到证据变得全面和可靠。
- 写作-反思循环:写作同样是一个迭代过程。写作智能体完成一部分草稿后,反思智能体会从清晰度、逻辑连贯性以及是否忠于原始证据等角度进行审查。写作智能体根据反馈进行修改,此过程不断重复,直到稿件的质量和准确性达标。
安装与部署
Maestro被设计为使用Docker容器化运行的应用程序,这简化了部署流程。
前提条件:
- Docker 和 Docker Compose:用于构建和运行容器化应用。
- Git:用于从GitHub克隆代码仓库。
- NVIDIA GPU:官方推荐使用,以获得最佳性能。
- 磁盘空间:需要约5GB,用于存放首次运行时自动下载的AI模型。
安装步骤:
- 克隆代码仓库首先,在你的终端或命令行工具中,使用
git命令将Maestro的源代码克隆到本地。git clone https://github.com/murtaza-nasir/maestro.git然后进入项目目录。
cd maestro - 配置环境Maestro提供了一个交互式的设置脚本来引导用户完成配置。运行以下命令:
./setup-env.sh该脚本会引导你设置网络配置(如访问地址和端口)、API密钥(用于连接大语言模型)以及其他必要的参数。完成后,它会自动为你创建一个
.env文件,其中包含了所有的环境配置。 - 构建并运行使用Docker Compose来构建镜像并以后台模式启动所有服务。
docker compose up --build -d这个命令会根据
docker-compose.yml文件的定义,拉取或构建所需的所有Docker镜像(包括前端、后端API等),然后启动容器。--build参数确保每次都使用最新的代码构建镜像,-d参数让容器在后台运行。 - 访问Maestro当所有容器成功运行后,你就可以通过在浏览器中访问你在第2步中配置的地址来打开Maestro的Web界面(例如:
http://localhost:3030)。首次登录的默认凭据是:- 用户名:
admin - 密码:
adminpass123官方强烈建议在首次登录后立即修改默认密码以确保安全。
- 用户名:
管理员操作
对于高级用户和管理员,Maestro提供了一个命令行界面(CLI)来执行批量文档上传、用户管理等任务。更详细的信息可以查阅项目中的DOCKER.md文件。
应用场景
- 学术研究对于学者和研究生,Maestro可以成为一个强大的助手。他们可以上传一个项目相关的所有参考文献(PDF格式),然后设定一个核心研究问题,例如“分析近年来关于强化学习在机器人控制中应用的主要挑战”。Maestro的智能体团队会自动阅读和理解这些论文,从网络上补充最新的信息,最终生成一份包含关键发现、不同论文观点对比和参考文献的综合性报告草稿。
- 市场与商业分析市场分析师需要处理大量的行业报告、新闻文章和财务报表。他们可以使用Maestro来快速提炼一个特定行业或公司的关键信息。例如,上传关于新能源汽车行业的多份报告,然后提出任务:“总结特斯拉、比亚迪和蔚来在2024年的技术创新、市场份额和未来挑战”。Maestro可以帮助分析师快速完成信息收集和初步整合,让他们能更专注于深度的洞察和策略制定。
- 内容创作与写作作家或内容创作者在撰写深度文章时,需要查阅大量资料。他们可以利用Maestro作为起点,定义文章主题并上传相关背景资料。Maestro不仅可以帮助他们整理出一份详细的内容大纲,还能根据大纲自动填充从资料中提取的笔记和数据,极大地提高了写作效率,并帮助克服“写作障碍”。
- 开发者与技术人员当需要学习一项新技术或解决一个复杂的技术问题时,开发者通常需要阅读大量的官方文档、技术博客和开源代码。他们可以将这些文档导入Maestro,然后提出具体问题,如“请解释Kubernetes中Service Mesh的工作原理并对比Istio和Linkerd的优缺点”。Maestro可以帮助他们快速构建起对复杂技术的系统性理解。
QA
- Maestro可以完全在没有互联网连接的情况下运行吗?可以。Maestro被设计为支持完全自托管的环境。通过配置使用本地部署的、与OpenAI API兼容的大语言模型(LLM),并集成私有的元搜索引擎SearXNG来替代公开的网页搜索,用户可以将整个研究工作流限制在自己的硬件上,无需与外部服务器进行数据交换。
- 使用Maestro是否需要付费?Maestro采用双重许可模式。它在AGPLv3(GNU Affero通用公共许可证第3版)下作为开源软件提供,用户可以免费使用和修改,但需要遵守AGPLv3的相关规定。对于无法遵守AGPLv3条款的组织或个人,项目方也提供商业许可证选项,可以联系维护者获取。
- 运行Maestro对硬件有什么具体要求?官方推荐使用NVIDIA GPU以获得最佳的AI模型推理性能。此外,系统在首次运行时会自动下载AI模型,需要大约5GB的磁盘空间。由于它作为Docker容器运行,理论上可以在任何支持Docker的操作系统(Windows、macOS、Linux)上部署。
- Maestro的AI智能体是如何确保研究质量的?Maestro通过其独特的“研究-反思”和“写作-反思”循环来保证质量。专门的反思智能体(Reflection Agent)会持续地审查其他智能体的工作,检查信息是否有遗漏、逻辑是否连贯、结论是否得到证据支持。这种内置的批判性审查机制模仿了人类的学术研究过程,通过不断的迭代和修正来提升最终报告的深度和准确性。